
はじめに
時系列データは、金融市場の価格変動や音声信号、生物学的測定など、多くの分野で重要な役割を果たしています。これらのデータを分析する際には、異なる時系列データ間の類似性を評価することが重要です。ここで活躍するのが、Dynamic Time Warping (DTW) という手法です。DTWは、時系列データの形状を比較するための強力なツールであり、異なる長さや異なる速度で進行するデータ間の類似性を評価することができます。
DTWの特徴
時系列の伸縮を考慮
DTWの最大の特徴は、時系列データの伸縮を考慮している点です。例えば、2つの時系列データが同じパターンを持っていても、一方が他方よりも速く進行する場合、従来のユークリッド距離では正確に比較できません。DTWは、この問題を解決するために、時間軸を動的に調整し、異なる速度で進行するデータ間の最適なマッチングを見つけ出します。
非線形なアライメント
DTWは、非線形な方法で時系列データを整列させることができます。これは、異なる長さの時系列データを比較する際に特に有用です。たとえば、歩行パターンの分析では、同じ人物が異なる速度で歩行した場合でも、DTWはその歩行パターンを正確に比較することができます。
局所的な変動に強い
DTWは、時系列データの局所的な変動に対しても頑健です。これは、ノイズや一時的な異常値が存在するデータを分析する際に重要です。DTWは、全体のパターンに基づいてデータを整列させるため、局所的な変動による影響を軽減することができます。
DTWの使い方
DTWの実装は、多くのプログラミング言語でサポートされています。ここでは、Pythonを使用してDTWを実装する方法を紹介します。Pythonには「dtaidistance」や「fastdtw」といったライブラリがあり、簡単にDTWを利用することができます。
dtaidistanceを使うと、距離を算出したり、データポイントの対応関係を線で結んで示してくれます。
import numpy as np
import matplotlib.pyplot as plt
from dtaidistance import dtw
# 2つの異なるパターンを持つ時系列データを生成
series1 = np.array([1, 7, 2, 3, 1, 5, 2, 1])
series2 = np.array([1, 2, 3, 4, 2, 1, 5, 1, 2, 3, 4])
# DTW距離とアライメントパスの計算
distance = dtw.distance(series1, series2)
path = dtw.warping_path(series1, series2)
# Series1とSeries2のプロット
fig, ax = plt.subplots(1, 2, figsize=(15, 5))
ax[0].plot(series1, label='Series 1')
ax[0].plot(series2, label='Series 2')
ax[0].set_title("Series 1とSeries 2の比較")
ax[0].set_xlabel("Index")
ax[0].set_ylabel("Value")
ax[0].legend()
# DTWの整列プロット
for (i, j) in path:
ax[1].plot([i, j], [series1[i], series2[j]], color='gray')
ax[1].plot(series1, label='Series 1')
ax[1].plot(series2, label='Series 2')
ax[1].set_title(f"DTW整列(距離: {distance:.2f})")
ax[1].set_xlabel("Index")
ax[1].set_ylabel("Value")
ax[1].legend()
plt.tight_layout()
plt.show()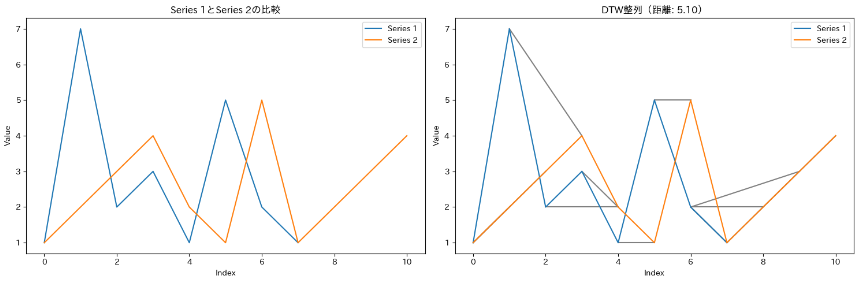
このようにDTWによる整列結果を含むプロットが生成されます。これにより、異なるパターンを持つ時系列データがDTWによってどのように整列されるかを視覚的に理解することができます。
まとめ
DTWを使用することで、異なる速度や長さの時系列データ間の類似性を効果的に評価できます。Pythonでの実装も簡単なので、興味のある方はぜひ試してみてください。これにより、DTWの整列効果をより明確に視覚化できると思います。


コメント