
はじめに
クラスタリングは、データ分析の一環として、データを似た傾向に基づいてグループに分ける手法です。その中でも特に有名で広く使われているのが「k-meansクラスタリング」です。この手法は、指定した数のクラスタ(k)にデータを分けることで、データの特性を理解しやすくします。この記事では、k-meansクラスタリングの基本概念、アルゴリズムの流れ、実際のコード例を交えながら解説していきます。
k-meansアルゴリズムの流れ
ステップ1. 初期化
- クラスタの数kを決定する。
- データセットからランダムにk個のポイントを選び、それらを初期クラスタ中心とする。
ステップ2. クラスタ割り当て
- 各データポイントに対して、最も近いクラスタ中心を見つけ、そのクラスタに割り当てる。この「近さ」は通常ユークリッド距離で測定されます。
ステップ3. クラスタ中心の更新
- 各クラスタに属するデータポイントの平均を計算し、それを新しいクラスタ中心とする。
ステップ4. 収束の確認
- クラスタ中心の位置が変わらなくなるまで、2と3を繰り返す。
k-meansクラスタリングの実際のコード例
以下に、Pythonを用いたk-meansクラスタリングのコード例を示します。使用するライブラリはscikit-learnです。
図の通り、いくつかのクラスタに分かれていることが分かります。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
import japanize_matplotlib
# サンプルデータの作成
n_samples = 300
random_state = 20
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
# k-meansクラスタリングの実行
k = 3
kmeans = KMeans(n_clusters=k)
kmeans.fit(X)
# クラスタリングの結果をプロット
plt.scatter(X[:, 0], X[:, 1], c=kmeans.labels_, s=50, cmap='viridis')
centers = kmeans.cluster_centers_
plt.scatter(centers[:, 0], centers[:, 1], c='red', s=200, alpha=0.75)
plt.title('k-meansクラスタリング結果')
plt.xlabel('Feature 1')
plt.ylabel('Feature 2')
plt.show()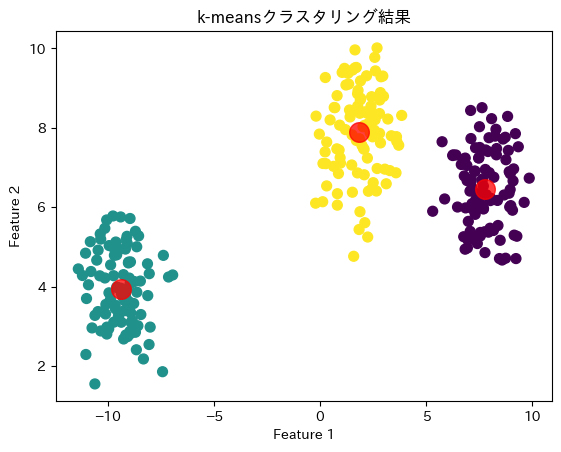
k-meansクラスタリングの応用
k-meansクラスタリングは、以下のような様々な分野で応用されています。
- マーケティング: 顧客を購入傾向や行動パターンに基づいてセグメント化し、ターゲットマーケティングを行う。
- 画像処理: 画像の色をクラスタリングして、色の量子化や画像のセグメンテーションを行う。
- 医療: 患者データをクラスタリングして、異なる病状や治療法の分析に役立てる。
まとめ
k-meansクラスタリングは、シンプルで効果的なクラスタリング手法として広く利用されています。データの特性を理解しやすくするために、k-meansを用いることで、様々な分野で有用な知見を得ることができます。Pythonを用いた実際のコードを参考に、ぜひ自分のデータセットで試してみてください。


コメント