
はじめに
決定木は機械学習において広く使用される強力なモデルの一つです。特に、その分類や回帰の能力と、モデルの解釈可能性から広く愛用されています。決定木が提供する重要な情報の一つが、各特徴量の重要度(importance)です。本記事では、決定木系モデルにおける特徴量重要度の算出方法と理解方法について解説します。
決定木モデルの概要
まず、決定木モデルの基本的な構造について理解しましょう。決定木は木構造を用いてデータを分類または回帰するモデルです。各ノード(節点)は特徴量を用いた条件分岐を表し、枝(エッジ)は条件の結果に基づいて分岐を示します。葉(リーフ)ノードは最終的な予測結果を表します。
特徴量重要度とは
特徴量重要度とは、モデルが予測を行う際に各特徴量がどれだけ重要であるかを示す指標です。つまり、その特徴量がモデルにとってどれだけ予測に寄与しているかを評価します。特徴量重要度は、モデルの解釈性や特徴量選択、データ理解に役立ちます。
XGBoostにおける特徴量重要度を紹介
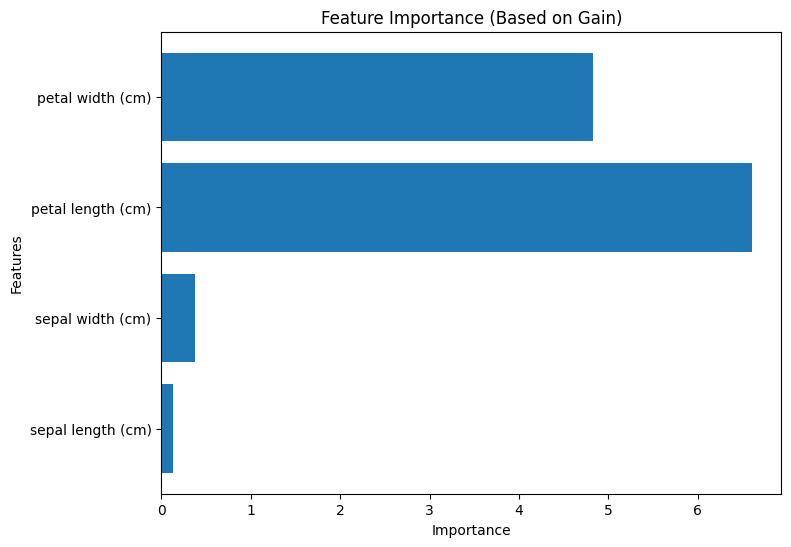
Gainに基づく重要度
Gainに基づく重要度は、各特徴量が分割された際の情報利得(Gain)に基づいて算出されます。情報利得は、分割前後の不純度の減少量を示す指標であり、分割がどれだけクラスを分離するかを評価します。Gainに基づく重要度は、各特徴量がモデルの性能向上にどれだけ貢献しているかを示します。
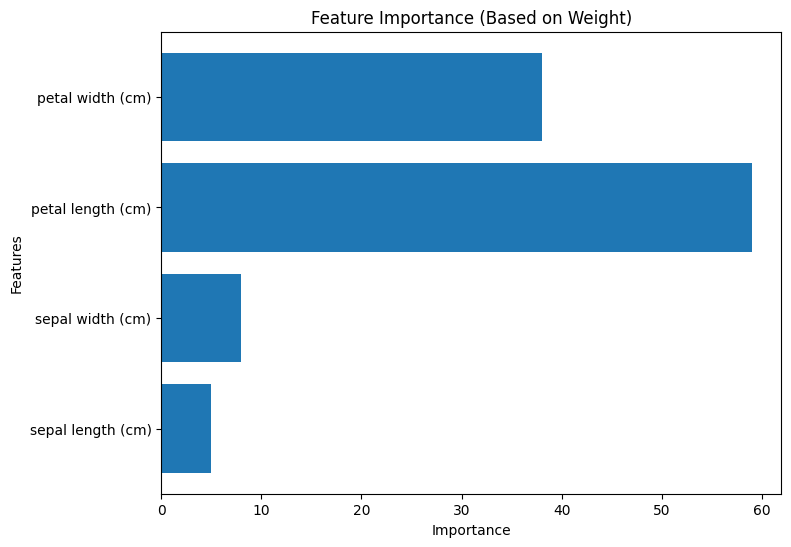
Weightに基づく重要度
Weightに基づく重要度は、各特徴量が分割に使用された回数(ウェイト)に基づいて算出されます。すなわち、各特徴量がモデルにおいてどれだけの頻度で重要な役割を果たしたかを示します。Weightに基づく重要度は、モデルがどの特徴量に焦点を当てて学習したかを表します。
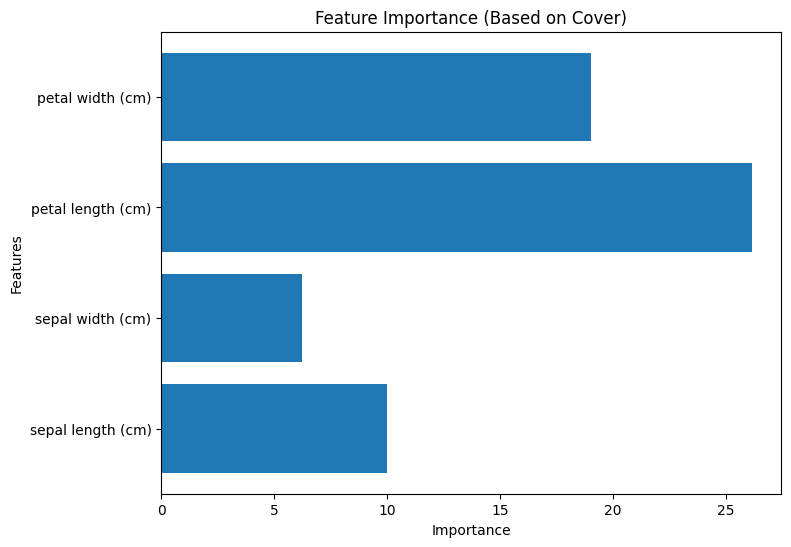
Coverに基づく重要度
Coverに基づく重要度は、各特徴量が分割によってカバーするデータポイントの数に基づいて算出されます。つまり、各特徴量がモデルによってどれだけのデータをカバーするかを評価します。Coverに基づく重要度は、特徴量がモデルにおいてどの程度広範囲なデータを表現するかを示します。
コード例と可視化
以下は、Pythonコードを使用してXGBoostモデルをトレーニングし、各重要度タイプを計算し、可視化する方法を示したものです。それぞれの手法で重要度が変わることが分かります。
import xgboost as xgb
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
# データの読み込み
iris = load_iris()
X = iris.data
y = iris.target
# XGBoostのデータセット形式に変換
dtrain = xgb.DMatrix(X, label=y)
# パラメータの設定
params = {'objective': 'multi:softmax', 'num_class': 3, 'seed': 42}
# モデルの学習
model = xgb.train(params, dtrain)
# 各重要度タイプごとの特徴量の重要度を取得
for importance_type in ['gain', 'weight', 'cover']:
importances = model.get_score(importance_type=importance_type)
# 特徴量の名前
feature_names = iris.feature_names
# 可視化
plt.figure(figsize=(8, 6))
plt.barh(feature_names, list(importances.values()))
plt.xlabel('Importance')
plt.ylabel('Features')
plt.title(f'Feature Importance (Based on {importance_type.capitalize()})')
plt.show()
まとめ
決定木系モデルにおける特徴量重要度は、モデルの解釈性や特徴量選択、データ理解に重要な情報を提供します。特徴量重要度を理解するためには、その算出方法や相対的な比較、視覚化、そしてドメイン知識の活用が不可欠です。これらの手法を組み合わせることでビジネス活用を進めていきましょう。


コメント