
はじめに
時系列データの分析や処理は、多くの分野で重要な課題です。例えば、金融市場の動向分析、センサーデータの異常検知、音声認識、健康データのモニタリングなど、さまざまな応用があります。これらの時系列データを効果的に扱うためには、似たパターンを見つける技術が不可欠です。今回は、そのような時系列データの類似性計算を簡単に実現できるPythonライブラリ「tslearn」の特徴と使い方について紹介します。
tslearnの特徴
「tslearn」は、時系列データの機械学習をサポートするためのオープンソースライブラリです。以下に、tslearnの主要な特徴を挙げます。
- 多様な距離計算方法:
- ユークリッド距離、ダイナミックタイムワーピング(DTW)、ソフトDTWなど、多様な距離計算アルゴリズムが実装されています。これにより、データの特性に応じた最適な距離計算方法を選択できます。
- 豊富なクラスタリング手法:
- k-means、DBA-k-means、時間的BIRCHなど、時系列データのクラスタリングに特化したアルゴリズムが利用可能です。
- 分類とレグレッション:
- k-NN分類器、k-NNレグレッサーなど、時系列データの分類と回帰のためのモデルも提供されています。
- 便利なデータ処理ツール:
- データの標準化、正規化、補間など、前処理に役立つ多くのユーティリティ関数が含まれています。
- 互換性と拡張性:
- scikit-learnとの互換性が高く、scikit-learnのパイプラインやグリッドサーチをそのまま利用することができます。
tslearnのインストール
tslearnは、Pythonの標準パッケージマネージャであるpipを使って簡単にインストールできます。
pip install tslearntslearnの基本的な使い方
以下に、tslearnを使った基本的な時系列データの類似性計算とクラスタリングの例を紹介します。
データの準備
まずは、サンプルデータを準備します。ここでは、tslearn自体が提供するデータセットを使用します。
import pandas as pd
import japanize_matplotlib
import matplotlib.pyplot as plt
from tslearn.datasets import CachedDatasets
from tslearn.preprocessing import TimeSeriesScalerMinMax
# データセットの読み込み
X_train, y_train, X_test, y_test = CachedDatasets().load_dataset("Trace")
# データのスケーリング
scaler = TimeSeriesScalerMinMax()
X_train_scaled = scaler.fit_transform(X_train)
X_test_scaled = scaler.transform(X_test)
# DataFrameに変換して表示
# ここでは各時系列の最初の10個の値を表示
df_train = pd.DataFrame([series.flatten()[:10] for series in X_train_scaled])
df_test = pd.DataFrame([series.flatten()[:10] for series in X_test_scaled])
print("Train Data (First 10 values of each series):")
print(df_train.head())
距離計算
次に、異なる時系列データ間の距離を計算してみます。ここでは、DTW(動的時間伸縮法)を使用します。
from tslearn.metrics import dtw
# DTW距離の計算
distance = dtw(X_train_scaled[0], X_train_scaled[1])
print(f"DTW距離: {distance}")
クラスタリング
時系列データのクラスタリングを行ってみましょう。ここでは、k-meansクラスタリングを使用します。
from tslearn.clustering import TimeSeriesKMeans
# k-meansクラスタリングの実行
model = TimeSeriesKMeans(n_clusters=3, metric="dtw")
y_pred = model.fit_predict(X_train_scaled)
print(f"クラスタリング結果: {y_pred}")
結果の可視化
最後に、クラスタリング結果を可視化します。
import matplotlib.pyplot as plt
# クラスタリング結果のプロット
for yi in range(3):
plt.subplot(3, 1, yi + 1)
for xx in X_train_scaled[y_pred == yi]:
plt.plot(xx.ravel(), "k-", alpha=0.2)
plt.plot(model.cluster_centers_[yi].ravel(), "r-")
plt.title(f"クラスタ {yi + 1}")
plt.tight_layout()
plt.show()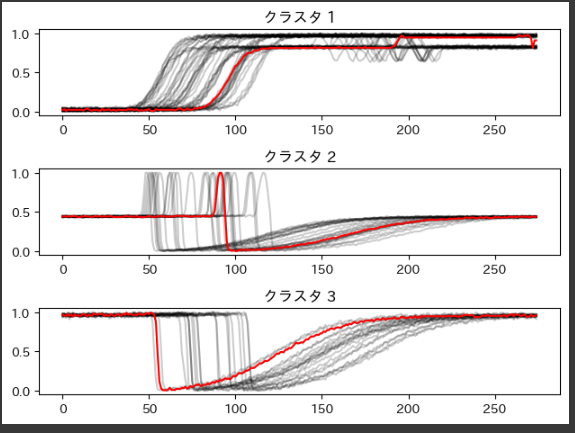
まとめ
「tslearn」は、時系列データの類似性計算やクラスタリングを手軽に行うための強力なツールです。豊富なアルゴリズムと高い拡張性を持ち、さまざまな時系列データの解析に対応しています。今回紹介した基本的な使い方を参考に、ぜひtslearnを使って自分のデータを分析してみてください。さらに詳しい情報や高度な使用方法については、公式ドキュメントを参照することをお勧めします。


コメント